为政企提供从模型到应用的一站式智能体落地解决方案
基于大模型的智能体应用平台,为政企及大型民营企业客户提供基于大模型智能应用落地的一体化解决方案

基于大模型的MaaS服务(模型即服务)
1.云上MaaS:依托基于大模型的智能体应用平台,智算中心强大算力,提供模型微调、推理等服务;
2.私域MaaS:提供预装开源大模型智能体应用平台的一站式交付方案
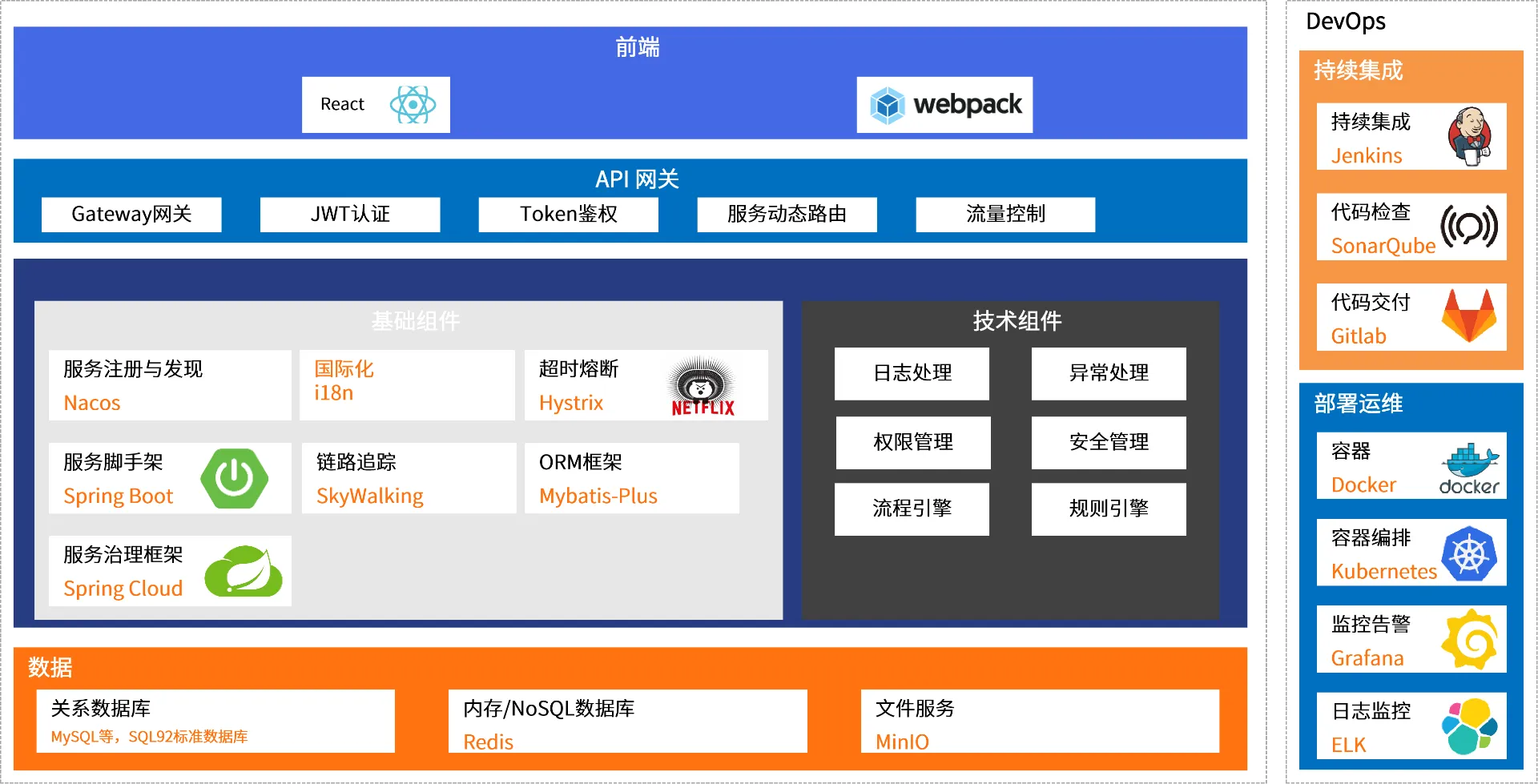
智能体应用平台
1.快速部署:一键完成云端资源部署、1周快速完成私域部署
2.一站式平台:涵盖智能体搭建、模型部署、开发工具、数据工具、分析工具、智能接入、统一权限、多租户等一站式平台功能
全面服务
1.支持国际主流算力芯片、国产算力芯片、支持国产数据库,全面支持主流大模型
2.智能体定制:大型企业或对AI性能要求极高等场景进行深入定制适配
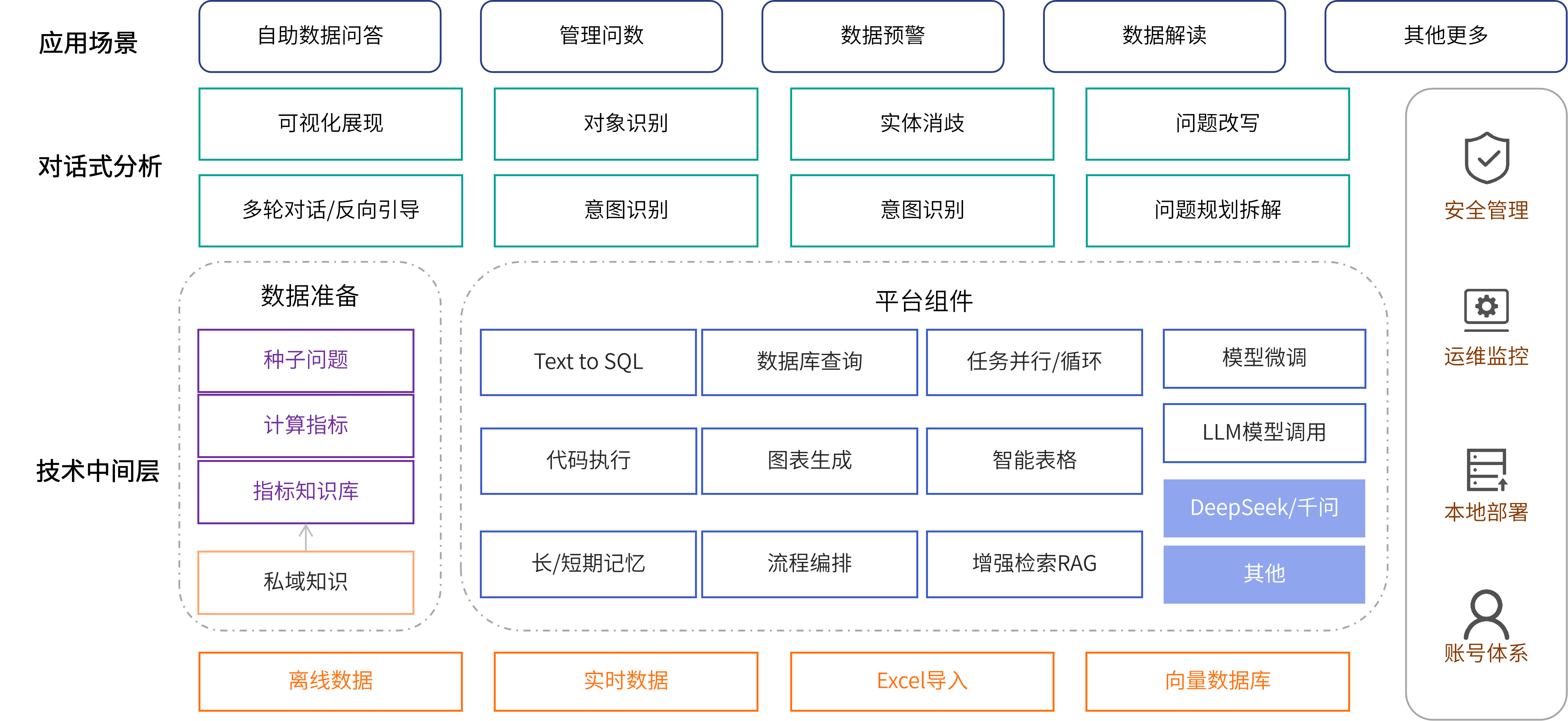
当用户提问不清晰时,系统通过反问引导用户澄清需求,并结合短期记忆存储,实现基于上下文逻辑的连续多轮对话。

支持导入数据表、字段、关联关系等元数据,配置别名与计算指标。通过增加Text to Metric的语义层,提升大模型对企业私有领域知识的理解能力,降低AI幻觉。

利用大语言模型(LLM)的语义理解能力,结合工程化处理手段,将用户多样化的描述方式改写为标准规范的问题,从而降低后续生成SQL的不确定性,提升整体准确率。

通过对指标波动的归因分析,自动识别业务中的关键影响因素,从而驱动业务的优化与提升。

据客户不同的业务需求,灵活调整功能模块,实现快速的定制化开发。

基于可感知的“前端对象化”技术,当用户输入问题时,采用类搜索引擎的推荐模式快速匹配维度/指标等对象,并结合实体消歧算法进一步消除歧义,精准识别查询对象。

分析数据的对比、差异、关系及变化趋势,将枯燥的数据表格转化为高可读性的数据洞见。

支持常见的排序、过滤、分组、聚合函数等SQL操作,复杂查询则支持窗口函数、嵌套子查询、分组排名等,支持多表关联查询,满足绝大部分使用场景需求。

该方案围绕RAG技术构建知识库问答体系,分知识库构建与问答检索两大环节。通过导入文件与内容清单,经解析、切片、增强后形成双知识库;问答时经问题改写、双库检索、重排序后,结合大模型输出精准结果。
整体架构分为知识库构建层、检索层、问答处理层等,各层功能独立且通过标准化接口交互。比如知识库构建层的文件解析、切片增强与检索层的倒排/语义检索互不干扰,便于单独优化某一层,降低系统维护成本。
搭建通用知识库和党建知识库,针对用户问题同时在两个库中并行检索。例如用户问“党建政策对业务的影响”,既通过关键词匹配通用政策文件,又用语义向量检索党建专属内容,覆盖更全面。
先通过倒排索引和语义检索召回初步结果,再用重排序模型对结果打分排序,筛选Top10。比如检索“经济指标波动原因”,先召回100条相关内容,经重排序后挑出与问题语义最契合的10条,提升答案精准度。
支持持续导入新文件,经切片、增强后自动更新到对应知识库。例如新增2026年党建政策文件,系统会解析内容、生成问答对并入库,确保知识库内容与业务/政策同步,避免知识滞后。
依托建广数科二十载技术沉淀与卓越的质量安全管理实力,AI智能体平台将CMMI五级、ISO等国际顶级认证标准贯穿于研发至运维的全流程。平台严格遵循国家安全规范,全方位保障系统稳健运行、数据安全传输及设备合规接入,致力于为企业数字化转型提供极致可靠的底层技术护航。




RAG知识库架构具备三大核心优势:通过动态更新保障知识时效性(>99%);利用Prompt工程与校验机制实现精准生成(幻觉率<3%);采用模块化设计支持多模态扩展,兼顾了数据的实时性、准确性与未来的可演进性。
支持政策变更、市场数据等场景下的知识库实时迭代,确保分析时效性达99%以上,避免知识滞后导致问答偏差。
通过Prompt工程与校验机制,将生成内容的幻觉率控制在3%以下,提升回答的准确性和可信度,减少错误信息输出。
采用模块化设计,支持多模态数据与Agent集成,未来可向边缘计算、联邦学习方向演进,适配不同行业的扩展需求。


留下您的联系方式,获取定制化数字转型方案